IBM Websphere Metadata
The J2EE 1.2 and EJB 1.1 specifications were a big step forward for enterprise Java TM developers.
This article explains how WebSphere uses metadata to map (CMP) container-managed persistence Enterprise JavaBeans to database tables.
They introduced a concept that enterprise applications had been missing for some time.
The metadata of a J2EE application could be read and written in a simple, easy-to-understand format, that is essentially plain text.
IBM has gotten behind this idea in a big way in WebSphere Application Server, Version 4.0 (WebSphere 4.0). This has some ramifications for developers working with WebSphere 4.0 and WebSphere Studio Application Developer (Application Developer), as we will see in this article.
They introduced a concept that enterprise applications had been missing for some time.
The metadata of a J2EE application could be read and written in a simple, easy-to-understand format, that is essentially plain text.
IBM has gotten behind this idea in a big way in WebSphere Application Server, Version 4.0 (WebSphere 4.0). This has some ramifications for developers working with WebSphere 4.0 and WebSphere Studio Application Developer (Application Developer), as we will see in this article.
What is metadata?
Metadata literally means "data about data". The parts of an application that aren't code, but describe the code and how it fits together with other code.
Metadata is information about a resource, such as an EJB or servlet, and about how it can be used by other J2EE resources.
An example of metadata is the EJB 1.1 Deployment Descriptor, which is described in [EJB 1.1].
Let us say you are building a simple EJB
The
The following deployment descriptor (named
Metadata is information about a resource, such as an EJB or servlet, and about how it can be used by other J2EE resources.
An example of metadata is the EJB 1.1 Deployment Descriptor, which is described in [EJB 1.1].
Let us say you are building a simple EJB
.jar file for deployment to WebSphere 4.0.The
.jar file contains a single container-managed persistence (CMP) entity bean that represents a person.The following deployment descriptor (named
ejb-jar.xml) is contained in the META-INF directory of our EJB .jar file, and describes our Person EJB:
<!DOCTYPE ejb-jar PUBLIC "-//Sun Microsystems,
Inc.//DTD Enterprise JavaBeans 1.1//EN"
"http://java.sun.com/j2ee/dtds/ejb-jar_1_1.dtd">
<ejb-jar>
<enterprise-beans>
<entity>
<ejb-name>PersonEJB</ejb-name>
<home>com.ibm.demo.ejbs.PersonHome</home>
<remote>com.ibm.demo.ejbs.Person</remote>
<ejb-class>com.ibm.demo.ejbs.PersonBean</ejb-class>
<persistence-type>Container</persistence-type>
<prim-key-class>java.lang.Integer</prim-key-class>
<reentrant>False</reentrant>
<cmp-field><field-name>id</field-name></cmp-field>
<cmp-field><field-name>name</field-name></cmp-field>
<cmp-field><field-name>age</field-name></cmp-field>
<cmp-field><field-name>educationLevel</field-name>
</cmp-field>
<primkey-field>id</primkey-field>
</entity>
</enterprise-beans>
<assembly-descriptor>
<security-role>
<description>
Everyone can gain access to this EJB.
</description>
<role-name>everyone</role-name>
</security-role>
<method-permission>
<role-name>everyone</role-name>
<method>
<ejb-name>PersonEJB</ejb-name>
<method-name>*</method-name>
</method>
</method-permission>
<container-transaction>
<method>
<ejb-name>PersonEJB</ejb-name>
<method-name>*</method-name>
</method>
<trans-attribute>Required</trans-attribute>
</container-transaction>
</assembly-descriptor>
</ejb-jar>
This simple deployment descriptor defines the parts of this EJB, such as the home interface, remote interface, bean class, and CMP fields, that are the fields in the bean class that will be container-managed. In other words, they will be stored and retrieved from a relational database by code generated during deployment. Finally, the deployment descriptor contains other information such as the container transaction settings and the EJB security roles defined for this bean.
This information is used by Websphere in the following ways: To determine how to handle transactions (whether to start a new transaction for each method, or to "flow" existing transactions through each EJB method). It is also used by the WebSphere security system to determine if a user (who is mapped by WebSphere to one or more J2EE roles) can access a particular EJB method.
This information is used by Websphere in the following ways: To determine how to handle transactions (whether to start a new transaction for each method, or to "flow" existing transactions through each EJB method). It is also used by the WebSphere security system to determine if a user (who is mapped by WebSphere to one or more J2EE roles) can access a particular EJB method.
WebSphere uses the metadata to determine how to generate the code for CMP persistence that will actually do the work of storing and retrieving information from a relational database.
This is exactly like a million other examples of deployment descriptors that you can find in other books and articles, and I doubt that most of you have learned anything new. I will not rehash what all the various tags in a deployment descriptor mean. Instead, let's find out what other metadata WebSphere uses in conjunction with EJBs, and how you can use that metadata in your own projects.
This is exactly like a million other examples of deployment descriptors that you can find in other books and articles, and I doubt that most of you have learned anything new. I will not rehash what all the various tags in a deployment descriptor mean. Instead, let's find out what other metadata WebSphere uses in conjunction with EJBs, and how you can use that metadata in your own projects.
Metadata in WebSphere 5.0
Let us begin by examining what happens when you generate the deployment code for this EJB using the WebSphere Application
Assembly Tool (AAT).[1] Remember that there are two forms of an EJB JAR:
We want to do here is to examine some of the information that WebSphere uses in this deployment process. WebSphere AE supports three methods for mapping CMP EJBs to a database:
- undeployed form: Contains only the remote and home interfaces, the bean implementation class, and the deployment descriptor.
- deployed form: Contains the classes that are necessary to support persistence, transactions, and distribution, and that are generated by the application server during deployment.
We want to do here is to examine some of the information that WebSphere uses in this deployment process. WebSphere AE supports three methods for mapping CMP EJBs to a database:
- Top-down: The information in the EJB is used to create a database table that corresponds to the managed fields of the CMP EJB.
- Meet-in-the-middle: There is a pre-specified correspondence between the managed fields in the CMP EJB and the columns in one or more database tables.
- Bottom-up: EJB fields are created for the columns in a database table.
The key point here is that WebSphere requires additional metadata beyond the EJB deployment descriptor to perform these mappings.
The metadata is used to drive the code generation process for the classes that actually execute specific SQL statements and then copy information out of the database tables into the EJB and vice versa.
If you can understand the metadata generated for a top-down mapping, then you are well on your way to understanding how to use WebSphere to map CMP EJBs to database tables via the meet-in-the-middle or bottom-up method.
If you use the WebSphere AAT to generate deployment code for an EJB JAR file, or deploy an undeployed EJB JAR file using the WebSphere Administration Console without specifying any additional information about database mapping, it will perform a top-down mapping. So, if you open the JAR file that contains this descriptor (attached) in AAT, generate the deployment code, and then expand the JAR into a directory, you will see that the META-INF directory now contains the following files:
If you use the WebSphere AAT to generate deployment code for an EJB JAR file, or deploy an undeployed EJB JAR file using the WebSphere Administration Console without specifying any additional information about database mapping, it will perform a top-down mapping. So, if you open the JAR file that contains this descriptor (attached) in AAT, generate the deployment code, and then expand the JAR into a directory, you will see that the META-INF directory now contains the following files:
/META-INF ejb-jar.xml MANIFEST.MF Map.mapxmi Table.ddl /Schema/schema.dbxmi
MANIFEST file
One of these files is expected, the MANIFEST file that is part of any JAR file, so we won't pay special attention to it. The other files are the interesting ones:
EJB-JAR.xml
The same as the one above, but modified by AAT to contain additional identification tags./Schema/schema.dbxm
Contains an XML representation of the database schema and table that the CMP EJB maps to.Map.mapxmi
Contains XML that shows how the CMP fields in theEJB-JAR.xmlfile map into the database schema in the schema file.Table.ddl
EJB-JAR.xml file. The part of the file below shows what changed:
<ejb-jar id="ejb-jar_ID">
<enterprise-beans>
<entity id="ContainerManagedEntity_1">
<ejb-name>PersonEJB</ejb-name>
<home>com.ibm.demo.ejbs.PersonHome</home>
<remote>com.ibm.demo.ejbs.Person</remote>
<ejb-class>com.ibm.demo.ejbs.PersonBean</ejb-class>
<persistence-type>Container</persistence-type>
<prim-key-class>java.lang.Integer</prim-key-class>
<reentrant>False</reentrant>
<cmp-field id="CMPAttribute_1">
<field-name>id</field-name>
</cmp-field>
<cmp-field id="CMPAttribute_2">
<field-name>name</field-name>
</cmp-field>
<cmp-field id="CMPAttribute_3">
<field-name>age</field-name>
</cmp-field>
<cmp-field id="CMPAttribute_4">
<field-name>educationLevel</field-name>
</cmp-field>
<primkey-field>id</primkey-field>
</entity>
</enterprise-beans>
...
</ejb-jar>
These id tags uniquely identify each CMP field within each Entity EJB contained in the JAR.
As we will see in a moment, this unique identification is crucial for WebSphere to operate correctly on the other metadata files.
The next file to become familiar with is not really a metadata file, but a file that WebSphere generates for your convenience.
This is the
As we will see in a moment, this unique identification is crucial for WebSphere to operate correctly on the other metadata files.
The next file to become familiar with is not really a metadata file, but a file that WebSphere generates for your convenience.
This is the
Table.ddl file, which contains the SQL to create the table for the top-down mapping:
CREATE TABLE PERSONEJB (ID INTEGER NOT NULL, NAME VARCHAR(250), AGE INTEGER, EDUCATIONLEVEL INTEGER); ALTER TABLE PERSONEJB ADD CONSTRAINT PERSONEJBPK PRIMARY KEY (ID);
If you carefully compare this file to the EJB deployment descriptor above, you will see that the table that corresponds to this EJB has the same name specified in the
<ejb-name> tag in the deployment descriptor, and that the columns of the table match the names in the <cmp-field> tags above. The column corresponding to the value of the <primkey-field> tag has been declared NOT NULL (since it will be the key for this table), and a primary key constraint has been added for this column as well. You may be wondering how WebSphere knows what datatypes to use to create this table. The answer is, there is a fixed mapping of datatypes in the database to the Java language types of the container-managed attributes defined in the code of your EJB Bean class. This mapping varies from database to database, which is why you must select the database type in either the AAT or the WebSphere Administration Console when you deploy the EJB to WebSphere. Now that you have seen the Table.ddl file and understand how WebSphere derived it from the code of your CMP EJB and the metadata in the EJB deployment descriptor, the next file to investigate is the schema.dbxmi file held in the Schema subdirectory of the META-INF directory:
<xmi:XMI xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI"
xmlns:RDBSchema="RDBSchema.xmi">
<RDBSchema:RDBDatabase xmi:id="RDBDatabase_1" name="TopDownDB"
tableGroup="RDBTable_1">
<dataTypeSet href="UDBV7_Primitives.xmi#SQLPrimitives_1"/>
</RDBSchema:RDBDatabase>
<RDBSchema:RDBTable xmi:id="RDBTable_1" name="PERSONEJB"
primaryKey="SQLReference_1" database="RDBDatabase_1">
<columns xmi:id="RDBColumn_1" name="ID" allowNull="false"
group="SQLReference_1">
<type xmi:type="RDBSchema:SQLExactNumeric"
xmi:id="SQLExactNumeric_1">
<originatingType xmi:type="RDBSchema:SQLExactNumeric"
href="UDBV7_Primitives.xmi#SQLExactNumeric_1"/>
</type>
</columns>
<columns xmi:id="RDBColumn_2" name="NAME">
<type xmi:type="RDBSchema:SQLCharacterStringType"
xmi:id="SQLCharacterStringType_1" length="250">
<originatingType xmi:type="RDBSchema:SQLCharacterStringType"
href="JavatoDB2UDBNT_V71TypeMaps.xmi#SQLCharacterStringType_250"/>
</type>
</columns>
<columns xmi:id="RDBColumn_3" name="AGE">
<type xmi:type="RDBSchema:SQLExactNumeric"
xmi:id="SQLExactNumeric_2">
<originatingType xmi:type="RDBSchema:SQLExactNumeric"
href="UDBV7_Primitives.xmi#SQLExactNumeric_1"/>
</type>
</columns>
<columns xmi:id="RDBColumn_4" name="EDUCATIONLEVEL">
<type xmi:type="RDBSchema:SQLExactNumeric"
xmi:id="SQLExactNumeric_3">
<originatingType xmi:type="RDBSchema:SQLExactNumeric"
href="UDBV7_Primitives.xmi#SQLExactNumeric_1"/>
</type>
</columns>
<namedGroup xmi:type="RDBSchema:SQLReference"
xmi:id="SQLReference_1"
name="PERSONEJBPK" members="RDBColumn_1" table="RDBTable_1"
constraint="Constraint_PERSONEJBPK"/>
<constraints xmi:id="Constraint_PERSONEJBPK" name="PERSONEJBPK"
type="PRIMARYKEY" primaryKey="SQLReference_1"/>
</RDBSchema:RDBTable>
</xmi:XMI>
It uses an XML standard called XMI, which represents information about an object design or object model in XML.
In fact, what it's describing is WebSphere's internal means of representing the database schema for this EJB. It is not intended to be as easily readable as the EJB deployment descriptor. However, it's not that hard to understand once you study it for a few minutes. Immediately after the opening XMI tag that describes the version and namespaces used by this file, you see the following tags:
In fact, what it's describing is WebSphere's internal means of representing the database schema for this EJB. It is not intended to be as easily readable as the EJB deployment descriptor. However, it's not that hard to understand once you study it for a few minutes. Immediately after the opening XMI tag that describes the version and namespaces used by this file, you see the following tags:
<RDBSchema:RDBDatabase xmi:id="RDBDatabase_1" name="TopDownDB" tableGroup="RDBTable_1"> <dataTypeSet href="UDBV7_Primitives.xmi#SQLPrimitives_1"/> </RDBSchema:RDBDatabase>
The only important thing about this group of tags is that it specifies that this particular schema uses the DB2- UDB 7 mapping to map Java types to database types. The next segment gets more interesting. Notice that these tags have the following structure as shown in Figure 1 below.
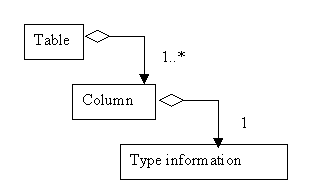
As you can see, there is a
Here we have an XML definition of the table. At first glance, this doesn't seem useful, since it is very similar to the information in the
<RDBSchema:RDBtable> tag that corresponds to the table defined in the CREATE TABLE SQL above. There are <columns> tags for each of the columns defined in the table as well. Finally, each <column> tag contains type information that describes both the originating type and the type of the column. The originating type provides information on the primitive database type (numeric, etc.), while the type tag shows how the originating type is extended for this particular column (by providing length, scale, or precision information).
Here we have an XML definition of the table. At first glance, this doesn't seem useful, since it is very similar to the information in the
Table.ddl file. However, the next file, the map.mapxmi file, brings everything together and helps all this make sense:
<ejbrdbmapping:EjbRdbDocumentRoot xmi:version="2.0"
xmlns:xmi="http://www.omg.org/XMI"
xmlns:ejbrdbmapping="ejbrdbmapping.xmi" xmlns:ejb="ejb.xmi"
xmlns:RDBSchema="RDBSchema.xmi" xmlns:Mapping="Mapping.xmi"
xmi:id="EjbRdbDocumentRoot_1" outputReadOnly="false" topToBottom="true">
<helper xmi:type="ejbrdbmapping:RdbSchemaProperies"
xmi:id="RdbSchemaProperies_1" primitivesDocument="DB2UDBNT_V71">
<vendorConfiguration
href="RdbVendorConfigurations.xmi#DB2UDBNT_V71_Config"/>
</helper>
<inputs xmi:type="ejb:EJBJar" href="META-INF/ejb-jar.xml#ejb-jar_ID"/>
<outputs xmi:type="RDBSchema:RDBDatabase"
href="META-INF/Schema/Schema.dbxmi#RDBDatabase_1"/>
<nested xmi:type="ejbrdbmapping:RDBEjbMapper" xmi:id="RDBEjbMapper_1">
<helper xmi:type="ejbrdbmapping:PrimaryTableStrategy"
xmi:id="PrimaryTableStrategy_1">
<table href="META-INF/Schema/Schema.dbxmi#RDBTable_1"/>
</helper>
<inputs xmi:type="ejb:ContainerManagedEntity"
href="META-INF/ejb-jar.xml#ContainerManagedEntity_1"/>
<outputs xmi:type="RDBSchema:RDBTable"
href="META-INF/Schema/Schema.dbxmi#RDBTable_1"/>
<nested xmi:id="PersonEJB_id---PERSONEJB_ID">
<inputs xmi:type="ejb:CMPAttribute"
href="META-INF/ejb-jar.xml#CMPAttribute_1"/>
<outputs xmi:type="RDBSchema:RDBColumn"
href="META-INF/Schema/Schema.dbxmi#RDBColumn_1"/>
<typeMapping
href="JavatoDB2UDBNT_V71TypeMaps.xmi#Integer-INTEGER"/>
</nested>
<nested xmi:id="PersonEJB_name---PERSONEJB_NAME">
<inputs xmi:type="ejb:CMPAttribute"
href="META-INF/ejb-jar.xml#CMPAttribute_2"/>
<outputs xmi:type="RDBSchema:RDBColumn"
href="META-INF/Schema/Schema.dbxmi#RDBColumn_2"/>
<typeMapping
href="JavatoDB2UDBNT_V71TypeMaps.xmi#String-VARCHAR"/>
</nested>
<nested xmi:id="PersonEJB_age---PERSONEJB_AGE">
<inputs xmi:type="ejb:CMPAttribute"
href="META-INF/ejb-jar.xml#CMPAttribute_3"/>
<outputs xmi:type="RDBSchema:RDBColumn"
href="META-INF/Schema/Schema.dbxmi#RDBColumn_3"/>
<typeMapping
href="JavatoDB2UDBNT_V71TypeMaps.xmi#int-INTEGER"/>
</nested>
<nested xmi:id="PersonEJB_educationLevel---PERSONEJB_EDUCATIONLEVEL">
<inputs xmi:type="ejb:CMPAttribute"
href="META-INF/ejb-jar.xml#CMPAttribute_4"/>
<outputs xmi:type="RDBSchema:RDBColumn"
href="META-INF/Schema/Schema.dbxmi#RDBColumn_4"/>
<typeMapping
href="JavatoDB2UDBNT_V71TypeMaps.xmi#int-INTEGER"/>
</nested>
</nested>
<typeMapping xmi:type="Mapping:MappingRoot"
href="JavatoDB2UDBNT_V71TypeMaps.xmi#Java_to_DB2UDBNT_V71_TypeMaps"/>
</ejbrdbmapping:EjbRdbDocumentRoot>
A few things are key to understanding how WebSphere EJB to RDB mapping works. It is not my intention to tell you how to generate this file from scratch, but instead to explain what it does so that you willl be able to make small changes to this file (and the others we've covered) in order to handle simple challenges in CMP mappings with WebSphere.
Start off by examining the following lines of code.
Start off by examining the following lines of code.
<inputs xmi:type="ejb:ContainerManagedEntity" href="META-INF/ejb-jar.xml#ContainerManagedEntity_1"/> <outputs xmi:type="RDBSchema:RDBTable" href="META-INF/Schema/Schema.dbxmi#RDBTable_1"/>
Here we have the first indication of what is going on. As you can see, these two lines link together a specific EJB reference in the
ejb-jar.xml file (ContainerManagedEntity_1, which was the id of the "PersonEJB" we saw earlier), with a particular database table defined in the schema (RDBTable_1, which is the PERSONEJB table previously seen in the schema file). In fact, if this were a multiple-table mapping (one where some columns came from two or more tables), you would see multiple <outputs> tags, each referring to a different schema file and table within that file . This same principle continues throughout the rest of the file, as the next section indicates:
<code> <nested xmi:id="PersonEJB_id---PERSONEJB_ID"> <inputs xmi:type="ejb:CMPAttribute" href="META-INF/ejb-jar.xml#CMPAttribute_1"> <outputs xmi:type="RDBSchema:RDBColumn" href="META-INF/Schema/Schema.dbxmi#RDBColumn_1"> <typeMapping href="JavatoDB2UDBNT_V71TypeMaps.xmi#Integer-INTEGER"> <nested > </code>
In this segment you see the connection between a particular container-managed field defined in the
If you are familiar with Converters in VisualAge� for Java EJB Support, you'll be relieved to know that the
ejb-jar.xml file (CMPAttribute_1, which is the field id) and a particular database column defined in the schema (RDBColumn_1, which is the ID column). After the input and output mappings are defined, the final piece to this puzzle is the type mapping -- which (as you can see) maps a Java type (Integer) to a relational database type (INTEGER). This kind of mapping is repeated for all of the CMP fields in the EJB. If you are familiar with Converters in VisualAge� for Java EJB Support, you'll be relieved to know that the
<typeMapping> tag is used to pick the default converter. If you need a different conversion than what is specified (say a specialized converter that knows how to convert the special Strings "Yes" and "No" to a boolean), you can specify this through a <helper> tag at this point.
Figure 2 below shows the interaction between these three primary XML files and their constituent parts.
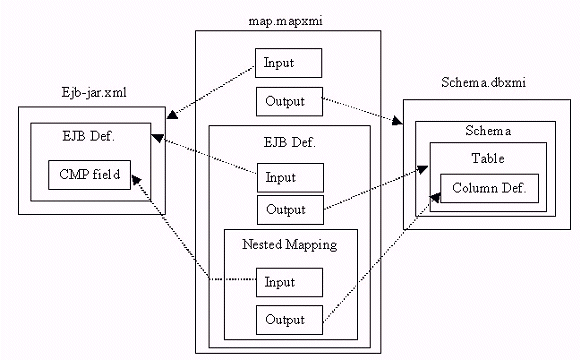
Simple Metadata Tricks
Now that you know about the existence, structure, and interrelationships of these XML files, the question is, what do you do with them?
First of all, let us clarify what you should not do with them.
You should not try to create these files in order to perform your own bottom-up or complex meet-in-the-middle mapping.
The reason is that the underlying schemas are not fully documented in the WebSphere documentation, because these files are intended to be generated and edited by the WebSphere toolset WebSphere Studio Application Developer
The Application Developer documentation contains the best description of the internal representation of the XMI object model that these files use.
If you are a tool builder who wants to generate your own entity EJBs using this information, consider using the documented Application Developer tool APIs to construct these files, rather than trying to reverse-engineer an object model from the XML.
On the other hand, there are a couple of instances where directly changing the XML can be the easiest way of updating your EJBs.
For example, many corporate environments have different database tables set up to support development, test, and production. In some cases, these databases may be hosted on the same instance of DB2 or Oracle, and only differ by schema name (you might have DEV.PERSONEJB, TEST.PERSONEJB and PROD.PERSONEJB).
How would you write your code so that it does not have any dependencies on what environment? In the case of CMP Entity EJBs, WebSphere makes it simple.
All you need to do is change the name of the schema in the schema tag, and then deploy the EJB JAR file to the different WebSphere instances used for the three environments. For example, for DEV, your tag might look like this:
First of all, let us clarify what you should not do with them.
You should not try to create these files in order to perform your own bottom-up or complex meet-in-the-middle mapping.
The reason is that the underlying schemas are not fully documented in the WebSphere documentation, because these files are intended to be generated and edited by the WebSphere toolset WebSphere Studio Application Developer
The Application Developer documentation contains the best description of the internal representation of the XMI object model that these files use.
If you are a tool builder who wants to generate your own entity EJBs using this information, consider using the documented Application Developer tool APIs to construct these files, rather than trying to reverse-engineer an object model from the XML.
On the other hand, there are a couple of instances where directly changing the XML can be the easiest way of updating your EJBs.
For example, many corporate environments have different database tables set up to support development, test, and production. In some cases, these databases may be hosted on the same instance of DB2 or Oracle, and only differ by schema name (you might have DEV.PERSONEJB, TEST.PERSONEJB and PROD.PERSONEJB).
How would you write your code so that it does not have any dependencies on what environment? In the case of CMP Entity EJBs, WebSphere makes it simple.
All you need to do is change the name of the schema in the schema tag, and then deploy the EJB JAR file to the different WebSphere instances used for the three environments. For example, for DEV, your tag might look like this:
<RDBSchema:RDBDatabase xmi:id="RDBDatabase_1" name="PROD" tableGroup="RDBTable_1">
You can automate simple substitution with tools like AWK, SED, or even ANT, which could also be used to invoke the appropriate WebSphere command-line tool (SEAppInstall on Advanced Single Server Edition, or WSCP on Advanced Edition) to generate the deployment code and install the resulting application.
In this case, you would start with an undeployed EJB JAR file, deploy it once, and then copy the metadata files described above back into the build tree of your project so that they become part of the undeployed JAR file.
When you deploy the JAR, WebSphere picks up the metadata files and generates the deployment code appropriately.
Another simple change you can make is to update the XML to perform a minimal meet-in-the-middle mapping when either the EJB definition or the database schema changes. For instance, suppose you decide later in the project to change the name of the educationLevel CMP field to edLevel. You'd only need to update the
In this case, you would start with an undeployed EJB JAR file, deploy it once, and then copy the metadata files described above back into the build tree of your project so that they become part of the undeployed JAR file.
When you deploy the JAR, WebSphere picks up the metadata files and generates the deployment code appropriately.
Another simple change you can make is to update the XML to perform a minimal meet-in-the-middle mapping when either the EJB definition or the database schema changes. For instance, suppose you decide later in the project to change the name of the educationLevel CMP field to edLevel. You'd only need to update the
ejb-jar.xml file to change the field like this:
<cmp-field id="CMPAttribute_4" > <field-name>edLevel>/field-name> </cmp-field >
Keep the id the same, because (as we saw earlier) the id is actually used to map the CMP field to the corresponding column in the schema. As you can imagine, a corresponding change in the database would involve keeping the
ejb-jar.xml the same, while updating the schema.dbxmi file appropriately. Again, in either case, redeploy the EJB jar file after editing the XML.
Summary
This article has examined some of the hidden parts of CMP EJB mapping to relational databases in WebSphere 4.0 and Application Developer. It described a little bit about how the ejb-jar, schema, and map files interoperate, and how the tools that operate on these files function. This information can help you make better use of the WebSphere tools for CMPs, and plan the best way to handle automated configuration and deployment issues involving CMPs.
Part 2 of this article will examine some of the other features of these files, such as associations, inheritance, converters, and composers, and also examine the ejb-jar extension file, which is used in custom finder methods for CMP EJBs.
Part 2 of this article will examine some of the other features of these files, such as associations, inheritance, converters, and composers, and also examine the ejb-jar extension file, which is used in custom finder methods for CMP EJBs.
AAT:[1]AAT can generate these documents for a top-down mapping, but you cannot edit them or perform the other mapping types directly in AAT.